
The other day, our tech lead suggested we implement supervised machine learning to automate our ticket approval system.
He said it would be very easy.
I had no idea how it worked-and honestly, I was confused. Why not just use if-else statements?
Problem Statement
We have a ticket approval system, a platform for reviewing tickets that request access to some resource. With an increasing number of tickets being submitted, manually reviewing them has become inefficient.
So, we are seeking a machine learning solution to automate this process.
What is Machine Learning
Machine learning is about extracting knowledge from data. Given tons of data, a machine learning model might discover the pattern and thus help people make predictions.
There are two most common types:
- Supervised learning algorithms learn from known input/output. Because we already know the answer, that’s why it’s called “supervised”. Common applications are like “Email spam detection” and “House price prediction”.
- Unsupervised learning algorithms only has known input. It’s more about grouping and finding the pattern. Common applications are like “Customer segmentation” and “Noise reduction”.
Apparently, we’re going to use supervised learning because we have both input (ticket compliance tags) and output (approved or not).
What Does Supervised Machine Learning Do
Supervised machine learning is used whenever we want to predict a certain output from a given input. The goal for our project is to make accurate predictions for incoming tickets-should we approve it or not.
Two major types of supervised machine learning problems:
- Classification: predict a class label, e.g. classifying irises into one of three possible species.
- Regression: predict a continuous number, e.g. predicting a person’s income from their education, ages, etc.
In our case, we just want to classify the new tickets into one of the few choices (approve, deny, escalate).
Why Not Just If-Else
Why can’t we just write a big if-else tree?
We human can mess up the complex logic. The problem can be really complicated: edge cases, exceptions, and duplication. Hardcoding the logic might not be a smart choice.
Instead of trying to figure out every feature, we can let machine learning model (like a decision tree) learns the logic based on data.
What is Decision Tree
Decision Trees learn a hierarchy of if/else questions and lead to a decision. We will build a model to distinguish the features instead of building it by hand.
Other algorithms include:
- K-Nearest Neighbors
- Lineal Models
- Naive Bayes
- Support Vector Machines
- Neural Networks
Among all those fancy algorithms, we chose ‘Decision Trees’. I don’t know why but let’s just assume this is the best algorithm in our case.
A Simple Example: Breast Cancer Classification
Let’s see a real-world example using the breast cancer dataset:
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=42)
tree = DecisionTreeClassifier(max_depth=4, random_state=0)
tree.fit(X_train, y_train)
print("Accuracy on training set: {:.3f}".format(tree.score(X_train, y_train)))
print("Accuracy on test set: {:.3f}".format(tree.score(X_test, y_test)))
Output:
Accuracy on training set: 0.988
Accuracy on test set: 0.951
After tuning the max_depth, we got a pretty accurate model.
Predicting Ticket Approvals
Let’s apply a similar approach to a (simplified) version of our ticket system.
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
# Sample data
data = {
'Sensitivity': ['L4', 'L4', 'L3', 'L2'],
'Department': ['HR', 'Dev', 'Dev', 'HR'],
'isCompliance': [True, False, False, False],
'inException': [False, True, False, False],
'Approval': ['No', 'Yes', 'No', 'Yes']
}
# Convert to DataFrame
df = pd.DataFrame(data)
# Encode categorical variables
df_encoded = pd.get_dummies(df.drop('Approval', axis=1))
y = df['Approval']
# Train decision tree
clf = DecisionTreeClassifier()
clf.fit(df_encoded, y)
# Predict on new examples
test = pd.get_dummies(pd.DataFrame([
{
'Sensitivity': 'L4',
'Department': 'Dev',
'isCompliance': True,
'inException': False
},
{
'Sensitivity': 'L4',
'Department': 'Security',
'isCompliance': False,
'inException': True
}
]))
test = test.reindex(columns=df_encoded.columns,
fill_value=0)
print(clf.predict(test)) # Output: ['No' 'Yes']
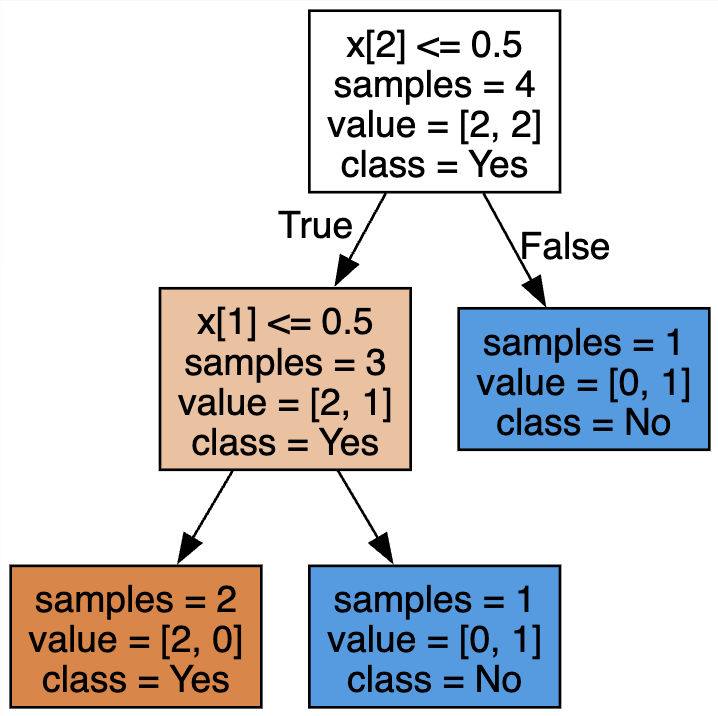
Visualizing the Tree.
# Display the tree
from sklearn.tree import export_graphviz
export_graphviz(clf, out_file="ticket.dot", class_names=["Yes", "No"],
impurity=False, filled=True)
import graphviz
from IPython.display import display
with open("ticket.dot") as f:
dot_graph = f.read()
graph = graphviz.Source(dot_graph)
display(graph)
Final Thoughts
I wasn’t a fan of AI back in school. I still remember my professor saying:
“AI is full of unsolved problems.”
I zoned out and got a B.
Even when ChatGPT came out, I mostly used it to help study cybersecurity. But once I started working in tech, AI became the elephant in the room. I couldn’t ignore it anymore.
Now I’m glad I didn’t. I’m still new to it, but I finally understand why machine learning is powerful—and I can’t wait to keep learning and applying it to real-world problems.
References
- Andreas C. Müller & Sarah Guido: (2016). Introduction to Machine Learning with Python: A Guide for Data Scientists. O’Reilly Media, Inc.
- Our AI friend: ChatGPT